Всё нижеследующее перевод вот этой странички, который я сделал для собственных целей, надеюсь он будет полезен и сообществу.
Nftables — все более популярный инструмент межсетевого экрана для Linux, заменяющий почтенный iptables. Большинство дистрибутивов Linux теперь предлагают первоклассную поддержку nftables; и хотя технически возможно использовать iptables и nftables вместе на одном и том же хосте, это обычно вызывает проблемы, поэтому вы должны выбрать только один из них для запуска на данном хосте.
Для хостов, на которых вы используете nftables, следуйте данному руководству, чтобы настроить простой брандмауэр, соответствующий топологии WireGuard, к которой принадлежит хост:
Основы Nftables
Nftables более мощный и гибкий, чем iptables, с соответственно более сложным синтаксисом. Хотя все еще возможно с помощью директивы PreUp наложить правила на цепочки nftables с помощью операторов в вашей конфигурации WireGuard, вероятно, лучше всего просто поместить их все в главный файл конфигурации nftables (или в файл, включенный в ваш главный файл конфигурации nftables). Большинство дистрибутивов используют либо /etc/nftables.conf или /etc/sysconfig/nftables.conf для этого главного файла конфигурации.
Установка Nftables
Debian
Главный файл конфигурации nftables для дистрибутивов на основе Debian (включая Ubuntu) находится по адресу /etc/nftables.conf. Вы можете установить пакет nftables с помощью следующей команды:
sudo apt install nftables
Fedora
Главный файл конфигурации nftables для дистрибутивов на основе Fedora (включая RHEL , CentOS, Amazon Linux, Oracle Linux и т. Д.) Находится по адресу /etc/sysconfig/nftables.conf. Вы можете установить пакет nftables с помощью следующей команды:
sudo dnf install nftables
Arch
Главный файл конфигурации nftables для Arch Linux находится по адресу /etc/nftables.conf. Вы можете установить пакет nftables с помощью следующей команды:
sudo pacman -S nftables
Alpine
Главный файл конфигурации nftables для Alpine Linux находится по адресу /etc/nftables.nft. Вы можете установить пакет nftables с помощью следующей команды:
sudo apk add nftables
Calculate linux (Gentoo)
Главный файл конфигурации nftables для Calculate linux находится по адресу /etc/conf.d/nftables Вы можете установить пакет nftables с помощью следующей команды:
emerge nftables
Запуск Nftables
Пакет nftables в большинстве дистрибутивов включает службу systemd, которая автоматически запускает nftables при загрузке, если вы выполните следующую команду:
sudo systemctl enable nftables
(Для дистрибутивов OpenRC, таких как Alpine, вместо этого запустите rc-update add nftables default.)
Вы можете перезапустить (или запустить, если он еще не запущен) эту службу systemd, чтобы перезагрузить конфигурацию nftables с помощью следующей команды:
sudo systemctl restart nftables
(Для дистрибутивов OpenRC, таких как Alpine или Gentoo, вместо этого запустите rc-service nftables restart.)
Если nftables не запускается, вы можете увидеть его сообщения об ошибках, выполнив следующую команду:
journalctl -u nftables
Базовая конфигурация
Ниже представлена базовая конфигурация nftables, которую мы будем использовать для всех примеров в этой статье:
#!/usr/sbin/nft -f
# очистить набор правил
flush ruleset
#Определяем публичный интерфейс
define pub_iface = "eth0"
#Определяем порт Wireguard
define wg_port = 51820
#Создаём таблицу фильтрации «плохих» пакетов
table netdev drop-bad-packets {
chain ingress {
# отбрасываем tcp "рождественские" пакеты (плохая комбинация флагов)
tcp flags & (fin | psh | urg) == fin | psh | urg drop
# отбрасываем tcp-пакеты без флагов
tcp flags & (fin | syn | rst | psh | ack | urg) == 0x0 drop
# отбрасываем tcp-пакеты с mss ниже минимального
tcp flags syn tcp option maxseg size 1-535 drop
}
chain ingress-eth0 {
type filter hook ingress device "eth0" priority -450; policy accept;
goto ingress
}
}
#Создаём таблицу фильтрации «плохих» состояний
table inet drop-bad-ct-states {
# предварительная маршрутизация цепи
chain prerouting {
type filter hook prerouting priority -150; policy accept;
# отбрасывать пакеты в "недопустимом (invalid)" состоянии отслеживания соединения
ct state invalid drop
# отбрасывать пакеты tcp для новых подключений, не являющихся пакетами синхронизации
ct state new tcp flags & (fin | syn | rst | ack) != syn drop
# сбросить новые подключения сверх установленного лимита скорости
ct state new limit rate over 1/second burst 10 packets drop
}
}
#Создаём основную таблицу фильтрации
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые (loopback) пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain forward {
type filter hook forward priority 0; policy drop;
reject with icmpx type host-unreachable
}
}
Сохраните его в /etc/conf.d/nftables (или там, где ваш дистрибутив Linux использует для своего главного файла конфигурации nftables, как описано выше). Измените его wg_port определение на ListenPort интерфейс хоста WireGuard (для «конечной точки A» в примерах в этой статье это будет 51821 взамен 5182 0 из базовой конфигурации выше). Измените его pub_iface определение на имя физического сетевого интерфейса хоста; и обновите chain ingress-eth0 блок, чтобы использовать то же имя.
Если ваш хост использует несколько физических интерфейсов (например, интерфейс WAN в eth0 и интерфейс LAN в eth1; или проводной интерфейс в ens3 и беспроводной интерфейс в и wls2 т.д.), добавьте каждый интерфейс в pub_iface определение:
define pub_iface = {"eth0", "eth1"}
… и создайте отдельную цепочку в таблице drop-bad-packets для каждого интерфейса:
chain ingress-eth0 {
type filter hook ingress device "eth0" priority -450; policy accept;
goto ingress
}
chain ingress-eth1 {
type filter hook ingress device "eth1" priority -450; policy accept;
goto ingress
}
В ingress цепочке в таблице drop-bad-packets есть некоторые правила для отбрасывания аномальных пакетов, используемых в основных атаках DOS (отказ в обслуживании). Он вызывается через ingress-eth0 цепочки для каждого интерфейса и т.д., которые подключаются к потоку пакетов Linux Netfilter как можно раньше (до дефрагментации пакетов и отслеживания соединений, как указано -450 приоритетом — подробности см. В документации Netfilter Hooks ).
prerouting цепочка в таблице drop-bad-ct-states содержат несколько правил, чтобы отбросить плохие пакеты и пакеты переполнения (flood), с помощью отслеживания соединений Netfilter. Он перехватывает путь предварительной маршрутизации Netfilter в стандартной mangleточке (приоритет -150) и отбрасывает пакеты с плохим состоянием отслеживания соединений, а также пакеты для новых соединений с превышением указанного предела скорости.
В зависимости от трафика, поступающего на хост, вы можете изменить это ограничение скорости. Ограничение в базовой конфигурации допускает создание пакетов из 10 новых подключений, а затем начинает отбрасывать пакеты для каждого нового подключения после этого, пополняя пул пакетов на один каждую секунду (с использованием стандартной методологии «token bucket» - подробности см. В документации Netfilter Limits ). :
ct state new limit rate over 1/second burst 10 packets drop
В таблице filter находятся основные правила межсетевого экрана. Цепочка input перехватывает входные пути netfilter (отправленные на хост пакеты), и цепочка forward перехватывает транзитные пути (пакеты пересылаются через хост). Базовая конфигурация отбрасывает все транзитные пакеты.
Для входного пути позволены:
- Петлевые пакеты (используются для обратной связи службами на хосте, связывающимися с самим хостом через сетевой сокет);
- Пакеты ICMP и ICMPv6 (используются для диагностики сети);
- Пакеты являются частью уже установленного соединения (обычно из соединений, установленных путем инициирования исходящего запроса, например соединения с внешним HTTP-сервером);
- Пакеты SSH отправленные на интерфейс
eth0(на TCP-порт22); - Пакеты WireGuard отправлены
eth0(на порт UDP51820согласно базовой конфигурации);
И он отбрасывает все остальное (отправляя в ответ пакет ICMP или ICMPv6 «Порт назначения недоступен» ).
Если вам не нужно удаленно администрировать хост, вы можете опустить правило SSH; или если вы знаете, что собираетесь подключаться по SSH к хосту только с определенного набора адресов, вы можете настроить его так, чтобы разрешить только эти исходные адреса. Например, вы можете ограничить SSH- соединения, чтобы разрешить их только от 198.51.100.1и 203.0.113.0/24 блока:
iif $pub_iface tcp dport ssh ip saddr { 198.51.100.1, 203.0.113.0/24 } accept
Точно так же, если вы знаете, что собираетесь подключаться через WireGuard к хосту только с определенного набора адресов, вы можете настроить правило WireGuard, чтобы оно разрешало только эти исходные адреса. Например, вы можете ограничить соединения WireGuard, чтобы разрешить их только от 203.0.113.2:
iif $pub_iface udp dport $wg_port ip saddr 203.0.113.2 accept
Замечание В остальных примерах, приведенных в этой статье, мы пропускаем таблицы drop-bad-packets и drop-bad-ct-states, так как их содержание шаблонно и не будет меняться от сценария к сценарию. Однако рекомендуется включать их (или аналогичные наборы правил) в каждую конфигурацию nftables, так как трафик, который они блокируют, никогда не является законным (за исключением трафика с ограничением скорости — вам может потребоваться увеличить лимит для сценариев с высоким трафиком), и они предотвращают некоторые базовые методы сетевой разведки и DOS-атаки.
Точка-точка
Таким образом, с помощью простого двухузлового двухточечного WireGuard VPN (виртуальная частная сеть), описанного в руководстве по настройке WireGuard Point-to-Point , мы можем настроить брандмауэр nftables на обеих точках (заменив брандмауэр iptables, описанный в «дополнительных» разделах руководства) в значительной степени с помощью базовой конфигурации .
Вот сетевая диаграмма сценария:
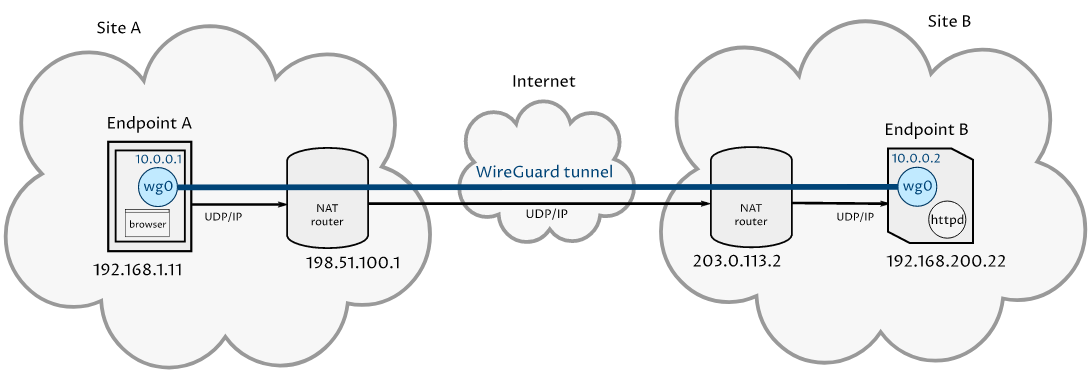
Рис. 1. Сценарий «точка-точка»
В этом сценарии оконечная точка A выполняет HTTP-запросы через WireGuard к оконечной точке B. Оконечной точке B никогда не требуется инициировать подключения к оконечной точке A (она просто отвечает на запросы от оконечной точки A).
Оконечная точка А
На оконечной точке A мы можем использовать нашу базовую конфигурацию nftables практически дословно. Единственное, что нам нужно настроить, - это wg_port определение. Измените его 51821 на порт, используемый для настройки WireGuard на конечной точке A:
define wg_port = 51821
Оконечная точка B
На оконечной точке B мы можем аналогично использовать нашу базовую конфигурацию nftables почти дословно. Нам также нужно изменить wg_portопределение, на этот раз на 51822, чтобы оно соответствовало порту, используемому для настройки WireGuard на конечной точке B :
define wg_port = 51822
Но нам также необходимо добавить дополнительное правило в input цепочку таблицы filter, чтобы разрешить доступ к HTTP-серверу конечной точки B. Если мы хотим разрешить любому другому хосту на сайте B доступ к этому серверу, а также к конечной точке A, мы можем сделать это, добавив следующее правило в конец цепочки input (непосредственно перед оператором reject):
tcp dport http accept
Если мы хотим ограничить доступ к HTTP-серверу, чтобы к нему могла получить доступ только конечная точка A (или любой другой хост, подключенный через тот же интерфейс WireGuard), мы можем сделать это вместо этого с помощью этого правила:
iifname "wg0" tcp dport http accept
Предупреждение Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйте iif(входной интерфейс по индексу) или oif(выходной интерфейс по индексу). Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйте iifname(входной интерфейс по имени) и oifname(выходной интерфейс по имени).
Правила , построенные с iifи oifвыражением хранить ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Если мы добавим определение wg_iface для wg0 интерфейса, полный /etc/conf.d/nftables файл для оконечной точки B (за вычетом таблиц drop-bad-packetsи drop-bad-ct-states, которые неизменны в каждом примере) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51822
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# принять все HTTP-пакеты, полученные на интерфейсе WireGuard
iifname $wg_iface tcp dport http accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain forward {
type filter hook forward priority 0; policy drop;
reject with icmpx type host-unreachable
}
}
Проверка
Проверьте это, попытавшись получить доступ к HTTP-серверу оконечной точки B из оконечной точки A:
$ curl 10.0.0.2
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
...
Вы должны увидеть напечатанный HTML-код домашней страницы оконечной точки B. Если вы запустите другой веб-сервер, работающий на оконечной точке B, на каком-либо другом порту, например, TCP-порт 8080 (запускается python3 -m http.server 8080 для временного сервера, обслуживающего содержимое текущего каталога), вы не сможете получить к нему доступ из оконечной точки A (или где-либо еще):
$ curl 10.0.0.2:8080
curl: (7) Failed to connect to 10.0.0.2 port 8080: Connection refused
Звезда
В топологии «Звезда» межсетевой экран nftables для периферийных устройств будет очень похож на точки в топологии «точка-точка». Концентратор также будет очень похож на базовую конфигурацию , но для этого потребуется хотя бы одно правило переадресации, чтобы разрешить перенаправление трафика от луча к лучу.
В качестве примера мы будем использовать концентратор и лучевую сеть WireGuard VPN, описанную в руководстве по настройке WireGuard Pdtplf . Вот сетевая диаграмма сценария:
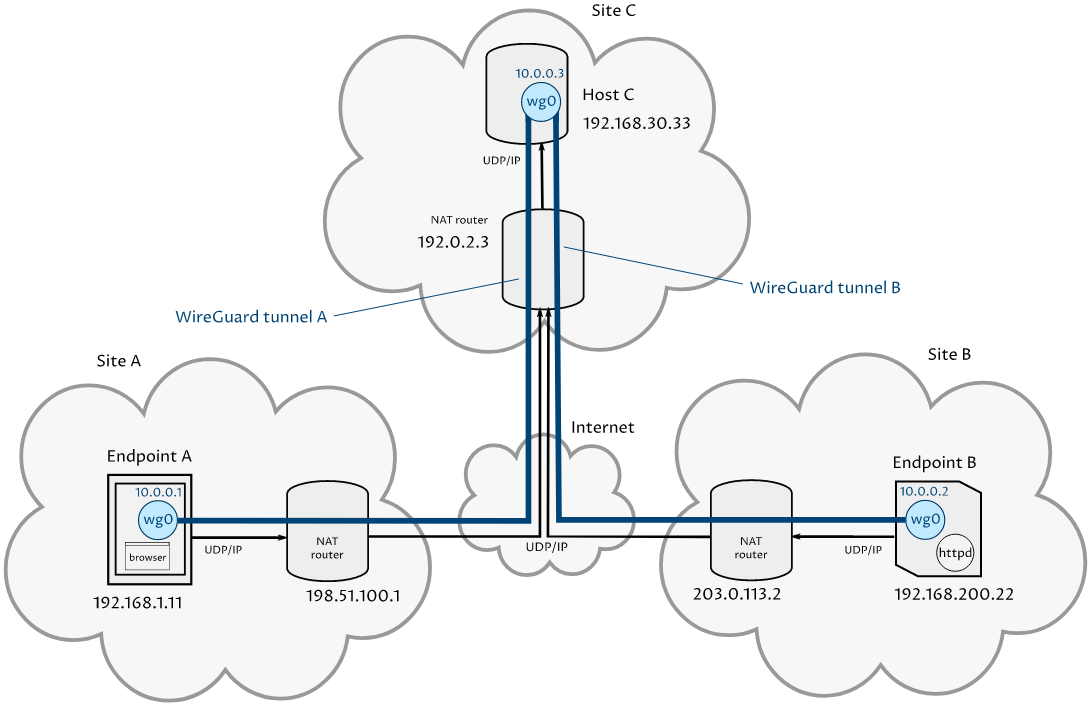
Рис. 2. Сценарий звезда (состоящий из концентратора «Host C» и лучей: «А-С» и «С-В»)
В этом сценарии оконечная точка A отправляет HTTP-запросы через хост C к оконечной точке B. Оконечной точке B никогда не требуется инициировать подключения к оконечной точке A (она просто отвечает на запросы, сделанные оконечной точкой A).
Конечная точка А
На конечной точке A мы можем использовать нашу базовую конфигурацию nftables практически дословно. Единственное, что нам нужно настроить, это определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на конечной точке A:
define wg_port = 51821
Оконечная точка B
На оконечной точке B мы можем аналогично использовать нашу базовую конфигурацию nftables почти дословно. Нам также нужно изменить определение wg_port, на этот раз 51822, чтобы оно соответствовало порту, используемому для настройки WireGuard на конечной точке B:
define wg_port = 51822
Однако нам также необходимо добавить дополнительное правило в цепочку input таблицы filter, чтобы разрешить доступ к HTTP-серверу оконечной точки B. Чтобы разрешить любому хосту в сети WireGuard доступ к нему, добавьте следующее правило в конец цепочки input (непосредственно перед оператором reject):
iifname "wg0" tcp dport http accept
Если бы мы хотели разрешить любому хосту в сети WireGuard неограниченный доступ к любой службе на конечной точке B (например, SSH , базам данных и другим сетевым приложениям), мы могли бы использовать вместо этого следующее правило:
iifname "wg0" accept
==Предупреждение==
Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйтеiif(входной интерфейс по индексу) илиoif(выходной интерфейс по индексу).
Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйтеiifname(входной интерфейс по имени) иoifname(выходной интерфейс по имени).
Правила , построенные сiifиoifвыражением хранят ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Хост C
В оконечной точке C нам нужно еще несколько изменений из нашей базовой конфигурации nftables. Нам действительно нужно изменить определение wg_port, на этот раз 51823, чтобы оно соответствовало порту, используемому для настройки WireGuard на хосте C:
define wg_port = 51823
И нам также нужно добавить несколько дополнительных правил в цепочку forward таблицы filter, чтобы разрешить пересылку пакетов между оконечными точками A и B.
Сначала давайте добавим определение для нашего имени интерфейса WireGuard:
define wg_iface = "wg0"
Затем, если мы хотим разрешить хосту C пересылать любой трафик с любого хоста в нашей сети WireGuard на любой другой хост, мы могли бы просто добавить следующее правило в цепочку forward таблицы filter (прямо перед правилом reject with icmpx type host-unreachable):
iifname $wg_iface oifname $wg_iface accept
Но если мы хотим использовать Host C для обеспечения соблюдения некоторых правил контроля доступа для нашей сети WireGuard, мы могли бы вместо этого создать отдельную цепочку фильтров только для него и активировать правило непосредственно в цепочке forward вместо перехода к нему для дополнительной фильтрации (goto это похоже на jump, но не возвращается назад — в этом случае нам не нужно будет возвращаться к цепочке forward):
iifname $wg_iface oifname $wg_iface goto wg-forward
Наименьшая версия этой цепочки wg-forward (которую мы поместили бы в нашу таблицу filter) выглядела бы так:
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 10.0.0.2 tcp dport http accept
# отклонить с вежливым "административно запрещенно" ответом icmp
reject with icmpx type admin-prohibited
}
В начале цепочки оно будет перенаправлять весь трафик ICMP и ICMPv6 с любого хоста в нашей сети WireGuard на любой другой хост, а также трафик для любых уже установленных соединений. И в конце цепочки он будет отклонять весь явно не принятый трафик (то есть большинство типов новых подключений), отбрасывая его и отвечая пакетом ICMP или ICMPv6 «Пункт назначения недоступен (обмен данными административно запрещен)».
Посередине мы поместили наши правила доступа WireGuard VPN. В минимальной версии выше мы разрешаем подключения к HTTP-серверу конечной точки B ( 10.0.0.2 TCP-порт 80) с любого хоста.
Более строгая версия этого правила может разрешить только точке A (10.0.0.1) доступ к HTTP-серверу точки B:
ip saddr 10.0.0.1 ip daddr 10.0.0.2 tcp dport http accept
Если есть несколько сервисов на точке В, которым мы хотим разрешить доступ к точке А, то мы могли бы изменить правило разрешив эти дополнительные услуги, как например (разрешает доступ к TCP портам 22, 80, 8080 и 8081):
ip saddr 10.0.0.1 ip daddr 10.0.0.2 tcp dport {ssh, http, 8080, 8081} accept
Или, если мы добавим к нашей сети еще пару оконечных устройств (скажем, 10.0.0.4 и 10.0.0.5), мы могли бы настроить правило, чтобы разрешить этим оконечным устройствам также доступ к HTTP-серверу оконечной точки B:
ip saddr {10.0.0.1, 10.0.0.4, 10.0.0.5} ip daddr 10.0.0.2 tcp dport http accept
В вышеупомянутых случаях мы могли бы вместо этого добавить несколько отдельных правил для отдельных серверов или служб; но с nftables немного эффективнее просто использовать наборы IP-адресов или портов в рамках одного правила (хотя вы заметите разницу только в том случае, если у вас много трафика или много правил).
В случаях, когда у нас есть несколько похожих правил, но с разными комбинациями исходного IP-адреса и целевого IP-адреса или порта, мы также можем использовать набор nftables с присоединением, чтобы объединить их все в одно правило. Например, если бы у нас была группа похожих правил, таких как следующие:
ip saddr 10.0.0.1 ip daddr 10.0.0.2 tcp dport http accept
ip saddr 10.0.0.4 ip daddr 10.0.0.2 tcp dport http accept
ip saddr 10.0.0.4 ip daddr 10.0.0.5 tcp dport http accept
ip saddr 10.0.0.1 ip daddr 10.0.0.5 tcp dport smtp accept
ip saddr 10.0.0.4 ip daddr 10.0.0.5 tcp dport smtp accept
Мы могли бы объединить их все в одном правиле , как это (где «.» является оператором конкатенация nftables):
ip saddr . ip daddr . tcp dport {
10.0.0.1 . 10.0.0.2 . http,
10.0.0.4 . 10.0.0.2 . http,
10.0.0.4 . 10.0.0.5 . http,
10.0.0.1 . 10.0.0.5 . smtp,
10.0.0.4 . 10.0.0.5 . smtp
} accept
==Примечание==
При использовании обоих IPv4 и IPv6 - адреса, вам нужно отдельноеip6правило (с одинаковым аргументамиsaddrиdaddr) для адресов IPv6 - вы не можете смешивать адреса IPv4 и IPv6 в одном выражении.
Полный файл /etc/conf.d/nftables для хоста C с минимальной цепочкой wg-forward, показанной выше (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51823
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# пересылать все HTTP-пакеты для оконечной точки B
ip daddr 10.0.0.2 tcp dport http accept
# отклонить icmp с вежливым "административно запрещено" ответом
reject with icmpx type admin-prohibited
}
chain forward {
type filter hook forward priority 0; policy drop;
# фильтровать пакеты, проходящие через сеть WireGuard через цепочку wg-forward
iifname $wg_iface oifname $wg_iface goto wg-forward
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
}
Проверка
Проверьте это, попытавшись получить доступ к HTTP-серверу точки B из точки A:
$ curl 10.0.0.2
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
...
Вы должны увидеть напечатанный HTML-код домашней страницы точки B. Если вы запустите другой веб-сервер, работающий на точке B, на каком-либо другом порту, например, TCP-порт 8080 (запускается python3 -m http.server 8080 для временного сервера, обслуживающего содержимое текущего каталога), вы не сможете получить к нему доступ из точки A (или где-либо еще):
$ curl 10.0.0.2:8080
curl: (7) Failed to connect to 10.0.0.2 port 8080: Connection refused
Точка-сайт
При стандартной топологии «точка-сайт» межсетевой экран nftables для точек будет очень похож на точки в топологии «точка-точка». Сайт также будет очень похож на базовую конфигурацию, но для перенаправления трафика от точек к сайту потребуется несколько дополнительных правил.
В качестве примера мы будем использовать WireGuard VPN типа «точка-сайт», описанную в руководстве WireGuard Point to Site Configuration. Вот сетевая диаграмма сценария:
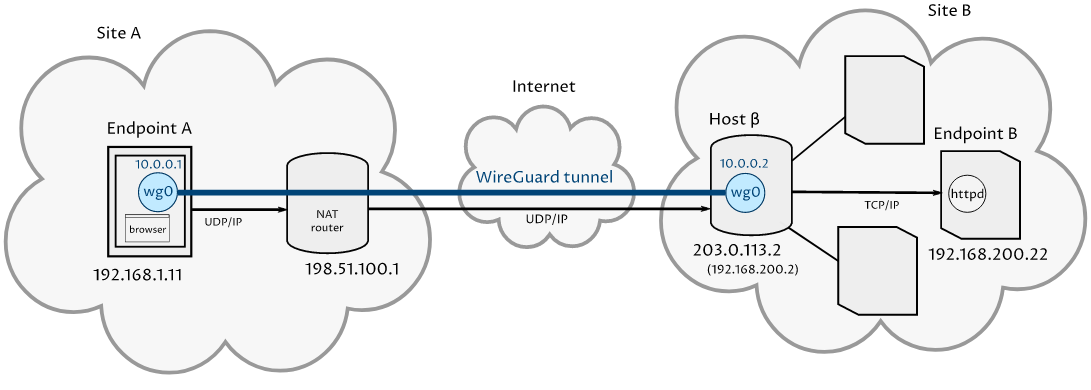
Рис. 3. Сценарий «Точка-сайт»
В этом случае точка A выполняет HTTP запросы через WireGuard-соединение с хостом β и далее до конечной точки B на сайте B LAN. Оконечной точке B никогда не требуется инициировать подключения к конечной точке A (она просто отвечает на запросы, сделанные оконечной точкой A).
Оконечная точка А
На конечной точке A мы можем использовать нашу базовую конфигурацию nftables практически дословно. Единственное, что нам нужно настроить, это определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на конечной точке A :
define wg_port = 51821
Конечная точка B
Конечная точка B в этом сценарии не является частью WireGuard VPN — это просто какой-то сервер в локальной сети на сайте B. Таким образом, хотя брандмауэр nftables для него будет очень похож на нашу базовую конфигурацию выше, ему не нужно будет принимать пакеты WireGuard; напротив, ему нужно будет принимать HTTP-пакеты. Минимальная конфигурация для него будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все пакеты SSH
tcp dport ssh accept
# принять все HTTP-пакеты
tcp dport http accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain forward {
type filter hook forward priority 0; policy drop;
reject with icmpx type host-unreachable
}
}
Для ограничения подключения к своему HTTP-серверу, чтобы он разрешал доступ только из нашей сети WireGuard (через Хост β, 192.168.200.2 в локальной сети Сайта B), настройте его HTTP-правило на следующее:
# принимать HTTP-пакеты от хоста β
ip saddr 192.168.200.2 tcp dport http accept
Хост β
На хосте β нам нужно внести еще несколько изменений в нашу базовую конфигурацию nftables. Нам также нужно изменить его определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на хосте β:
define wg_port = 51822
Также в верхней части конфигурации давайте добавим определение для нашего имени интерфейса WireGuard:
define wg_iface = "wg0"
Затем, в нижней части, добавим новую таблицу nat с цепочкой postrouting, которая будет маскарадить пакеты от WireGuard VPN на сайт Б локальной сети:
table inet nat {
chain postrouting {
type nat hook postrouting priority 100; policy accept;
iifname $wg_iface oif $pub_iface masquerade
}
}
Имя таблицы и цепочки произвольное — важно то, что цепочка type установлена в nat, с postrouting-приоритетом ловушки 100 (приоритет в пути постмаршрутизации, где должен применяться SNAT). Правило masquerade в этой цепочке будет переводить исходный адрес любых пакетов, которые хост β перенаправляет от подключенных к нему WireGuard пиров, переписывая их для использования собственного адреса хоста β на Сайте В локальной сети (192.168.200.2). Для ответов на эти пакеты он будет делать обратное - транслировать пункт назначения пакета из собственного адреса хоста β в IP-адрес однорангового узла WireGuard, который был исходным источником.
==Примечание==
Если на хосте β используется версия ядра Linux старше 5.2 (выпущенная в середине 2019 года), установите тип таблицыnatвместоipinet(илиip6если вы используете адреса IPv6).
И если ядро Host β старше 4.18 (выпущено в середине 2018 г.), вам также необходимо добавитьpreroutingв таблицуnatследующую цепочку:
chain prerouting {
type nat hook prerouting priority -100; policy accept;
}
Несмотря на то, что эта цепочка не содержит никаких правил, она необходима для более старых ядер, чтобы гарантировать, что ответы на замаскированные пакеты правильно транслируются обратно в исходный источник.
Наконец, если мы хотим разрешить хосту β пересылать весь трафик с любого хоста в нашей сети WireGuard на любой хост в сайте B, мы могли бы добавить следующие два правила в цепочку forward его таблицы filter (прямо перед правилом reject with icmpx type host-unreachable):
ct state established,related accept
iifname $wg_iface oif $pub_iface accept
==Предупреждение==
Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйтеiif(входной интерфейс по индексу) илиoif(выходной интерфейс по индексу).
Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйтеiifname(входной интерфейс по имени) иoifname(выходной интерфейс по имени).
Правила , построенные сiifиoifвыражением хранят ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Однако, если мы хотим использовать Host β для обеспечения соблюдения некоторых правил контроля доступа для нашей сети WireGuard, мы могли бы вместо этого создать отдельную цепочку фильтров только для нее, переходя от цепочки forward к ней для дополнительной фильтрации. В этом случае вместо этого добавьте в цепочку forward следующие два правила:
ct state established,related accept
iifname $wg_iface oif $pub_iface goto wg-forward
Затем добавьте следующую цепочку wg-forward в таблицу filter:
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 192.168.200.22 tcp dport http accept
# отклонить с вежливым "административно запрещен" ответом icmp
reject with icmpx type admin-prohibited
}
Первые правила в этой цепочке перенаправляют весь ICMP и ICMPv6 трафик с любого хоста в нашей WireGuard сети к любому хосту на сайте B LAN. Последнее правило в цепочке отклоняет весь явно не принятый трафик (т.е. большинство типов новых подключений), отбрасывая его и отвечая пакетом ICMP или ICMPv6 «Адресат недоступен (обмен данными административно запрещен)».
Посередине у нас есть правила доступа WireGuard VPN. В минимальной версии выше мы разрешаем все подключения к HTTP-серверу точки B (192.168.200.22 TCP-порт 80) с любого хоста.
Более строгая версия этого правила может разрешить только точке A (10.0.0.1) доступ к HTTP-серверу точки B :
ip saddr 10.0.0.1 ip daddr 192.168.200.22 tcp dport http accept
Если есть несколько сервисов на точке В, которым мы хотим разрешить доступ к точке А, то мы могли бы изменить правило разрешив эти дополнительные услуги, как например (разрешает доступ к TCP портам 22, 80, 8080 и 8081):
ip saddr 10.0.0.1 ip daddr 10.0.0.2 tcp dport {ssh, http, 8080, 8081} accept
Или, если мы добавим к нашей сети еще пару оконечных устройств (скажем, 10.0.0.4 и 10.0.0.5), мы могли бы настроить правило, чтобы разрешить этим оконечным устройствам также доступ к HTTP-серверу оконечной точки B:
ip saddr {10.0.0.1, 10.0.0.4, 10.0.0.5} ip daddr 10.0.0.2 tcp dport http accept
В вышеупомянутых случаях мы могли бы вместо этого добавить несколько отдельных правил для отдельных серверов или служб; но с nftables немного эффективнее просто использовать наборы IP-адресов или портов в рамках одного правила (хотя вы заметите разницу только в том случае, если у вас много трафика или много правил).
В случаях, когда у нас есть несколько похожих правил, но с разными комбинациями исходного IP-адреса и целевого IP-адреса или порта, мы также можем использовать набор nftables с присоединением, чтобы объединить их все в одно правило. Например, если бы у нас была группа похожих правил, таких как следующие:
ip saddr 10.0.0.1 ip daddr 10.0.0.2 tcp dport http accept
ip saddr 10.0.0.4 ip daddr 10.0.0.2 tcp dport http accept
ip saddr 10.0.0.4 ip daddr 10.0.0.5 tcp dport http accept
ip saddr 10.0.0.1 ip daddr 10.0.0.5 tcp dport smtp accept
ip saddr 10.0.0.4 ip daddr 10.0.0.5 tcp dport smtp accept
Мы могли бы объединить их все в одном правиле, как это (где «.» является оператором конкатенация nftables):
ip saddr . ip daddr . tcp dport {
10.0.0.1 . 10.0.0.2 . http,
10.0.0.4 . 10.0.0.2 . http,
10.0.0.4 . 10.0.0.5 . http,
10.0.0.1 . 10.0.0.5 . smtp,
10.0.0.4 . 10.0.0.5 . smtp
} accept
==Примечание==
При использовании обоих IPv4 и IPv6-адреса, вам нужно отдельноеip6-правило (с одинаковым аргументамиsaddrиdaddr) для адресов IPv6 - вы не можете смешивать адреса IPv4 и IPv6 в одном выражении.
Полный файл /etc/conf.d/nftables для хоста β с минимальной цепочкой wg-forward, показанной выше (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51822
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 192.168.200.22 tcp dport http accept
# отклонить с вежливым "административно запрещено" ответом icmp
reject with icmpx type admin-prohibited
}
chain forward {
type filter hook forward priority 0; policy drop;
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# фильтруем все пакеты от WireGuard VPN до Сайта B через цепочку wg-forward
iifname $wg_iface oif $pub_iface goto wg-forward
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
}
table inet nat {
chain postrouting {
type nat hook postrouting priority 100; policy accept;
# замаскировать все пакеты от WireGuard VPN до Сайта B
iifname $wg_iface oif $pub_iface masquerade
}
}
Проверка
Проверьте это, попытавшись получить доступ к HTTP-серверу точки B из точки A:
$ curl 192.168.200.22
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
...
Вы должны увидеть напечатанный HTML-код домашней страницы точки B. Если вы запустите другой веб-сервер, работающий на точке B, на каком-либо другом порту, например, TCP-порт 8080 (запускается python3 -m http.server 8080 для временного сервера, обслуживающего содержимое текущего каталога), вы не сможете получить к нему доступ из точки A (или где-либо еще):
$ curl 192.168.200.22:8080
curl: (7) Failed to connect to 192.168.200.22 port 8080: Connection refused
Точка-сайт с переадресацией портов
Если у вас есть топология «точка-сайт», но вы хотите «изменить» направление доступа, чтобы хосты изнутри сайта инициировали доступ к службам на точках, а не наоборот, то вам необходимо настроить несколько разных правил nftables на сайте и точках, чем в стандартной конфигурации Точка-сайт.
В качестве примера мы будем использовать WireGuard VPN типа «точка-сайт», описанную в руководстве WireGuard Point to Site With Port Forwarding. Вот сетевая диаграмма сценария:
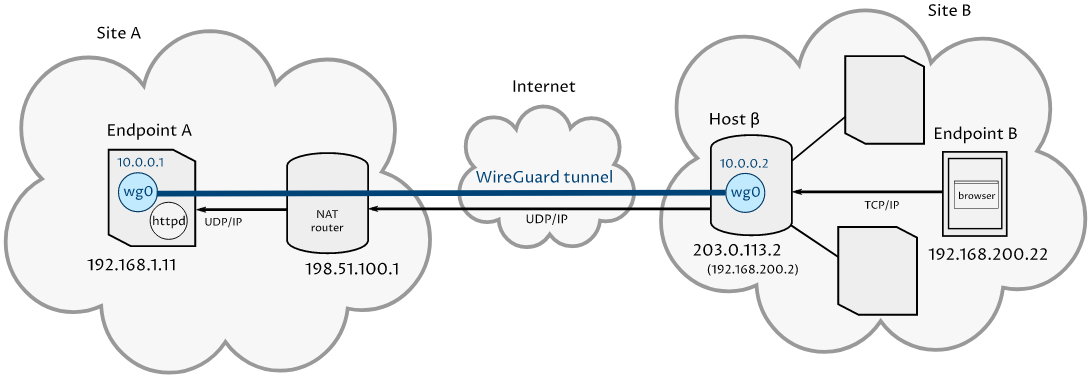
Рисунок 4. Точка-сайт с переадресацией портов.
В этом сценарии точка B на сайте B отправляет HTTP-запросы через хост β к конечной точке A в WireGuard VPN. Конечная точка A не инициирует подключения к сайту B — она просто отвечает на запросы, которые она получает от хоста β.
Конечная точка А
На конечной точке A мы можем начать с нашей базовой конфигурации nftables и добавить одно дополнительное правило, разрешающее доступ к HTTP-службе конечной точки A. Однако сначала нам нужно изменить его определение wg_port на 51821, чтобы оно соответствовало порту, используемому для настройки WireGuard на конечной точке A :
define wg_port = 51821
Затем добавьте правило в цепочку input таблицы filter, чтобы разрешить доступ к HTTP-серверу, работающему на конечной точке A. Если мы хотим разрешить доступ с любого хоста на сайте A или сайте B, мы могли бы добавить правило, подобное следующему, внизу в цепочке input (непосредственно перед утверждением reject):
tcp dport http accept
Однако, если мы хотим ограничить доступ, чтобы только хосты на сайте B имели доступ, мы можем сделать это вместо этого с помощью этого правила:
iifname "wg0" tcp dport http accept
==Предупреждение==
Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйтеiif(входной интерфейс по индексу) илиoif(выходной интерфейс по индексу).
Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйтеiifname(входной интерфейс по имени) иoifname(выходной интерфейс по имени).
Правила , построенные сiifиoifвыражением хранят ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Если мы добавим определение wg_iface для интерфейса wg0, полный файл /etc/conf.d/nftables для конечной точки А с минимальной цепочкой wg-forward, показанной выше (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51821
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все пакеты icmp / icmpv6
iif "lo" accept
# принять все петлевые пакеты
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# принять все HTTP-пакеты, полученные на интерфейсе WireGuard
iifname $wg_iface tcp dport http accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain forward {
type filter hook forward priority 0; policy drop;
reject with icmpx type host-unreachable
}
}
Конечная точка B
Конечная точка B в этом сценарии не является частью WireGuard VPN — это просто какой-то компьютер в локальной сети на сайте B. Если вы хотите настроить для него брандмауэр nftables, используйте базовую конфигурацию исключив строку iif $pub_iface udp dport $wg_port accept в ней.
Хост β
На хосте β мы снова начнем с нашей базовой конфигурации nftables и добавим к ней еще несколько правил. Сначала измените его определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на хосте β :
define wg_port = 51822
Также в верхней части конфигурации добавьте определение для нашего имени интерфейса WireGuard:
define wg_iface = "wg0"
Затем внизу добавьте новую таблицу nat с цепочкой prerouting, содержащую правило для перенаправления TCP-порта 80 на конечную точку A (10.0.0.1):
table inet nat {
chain prerouting {
type nat hook prerouting priority -100; policy accept;
tcp dport http dnat ip to 10.0.0.1
}
}
Имя таблицы и цепочки произвольное — важно то, что цепочка установлена в type nat, с prerouting-приоритетом ловушки -100 (приоритет в пути предварительной маршрутизации, где должен применяться DNAT). Правило dnat в этой цепочке будет переводить в адрес назначения любые получаемые хостом β TCP-пакеты с порта назначения 80, на оконечную точку A с IP-адресом 10.0.0.1 в качестве пункта назначения. Для ответов на эти пакеты он будет делать обратное — преобразовать адрес источника ответного пакета 10.0.0.1 обратно в собственный адрес хоста β в локальной сети сайта B (192.168.200.2).
==Примечание==
Если на хосте β используется версия ядра Linux старше 5.2 (выпущенная в середине 2019 года), установите тип таблицыnatвместоipinet(илиip6если вы используете адреса IPv6).
И если ядро Host β старше 4.18 (выпущено в середине 2018 г.), вам также необходимо добавить следующую цепочкуpreroutingв таблицуnat:
chain prerouting {
type nat hook prerouting priority -100; policy accept;
}
Несмотря на то, что эта цепочка не содержит никаких правил, она необходима для более старых ядер, чтобы гарантировать, что ответы на замаскированные пакеты правильно транслируются обратно в исходный источник.
Если вы также хотите преобразовать порт — например, перенаправить порт 8080 на хосте β на порт 80 на конечной точке A — добавьте переведенный порт к переведенному адресу:
tcp dport 8080 dnat ip до 10.0.0.1:80
Если вы хотите перенаправить несколько портов, вы можете добавить одно правило для каждого порта:
tcp dport 8080 dnat ip to 10.0.0.1:80
tcp dport 8443 dnat ip to 10.0.0.1:443
tcp dport 8993 dnat ip to 10.0.0.1:993
tcp dport 8084 dnat ip to 10.0.0.4:80
tcp dport 8085 dnat ip to 10.0.0.5:80
В недавно выпущенной версии 1.0.0 nftables вы можете альтернативно объединить несколько правил назначения ip:port в одно правило с удобным map синтаксисом (хотя вам по-прежнему нужны отдельные правила для портов TCP и UDP , а также для адресов IPv4 и IPv6):
dnat ip to tcp dport map {
8080 : 10.0.0.1 . 80,
8443 : 10.0.0.1 . 443,
8993 : 10.0.0.1 . 993,
8084 : 10.0.0.4 . 80,
8085 : 10.0.0.5 . 80
Последний шаг — разрешить Хосту β пересылать пакеты с переведенными адресами назначения. Если мы хотим разрешить хосту β пересылать переведенные пакеты с любого хоста на сайте B, мы могли бы добавить следующие два правила в цепочку forward таблицы filter (прямо перед правилом reject with icmpx type host-unreachable):
ct state established,related accept
iif $pub_iface oifname $wg_iface accept
==Предупреждение==
Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйтеiif(входной интерфейс по индексу) илиoif(выходной интерфейс по индексу).
Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйтеiifname(входной интерфейс по имени) иoifname(выходной интерфейс по имени).
Правила , построенные сiifиoifвыражением хранят ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Однако, если мы хотим использовать Host β для обеспечения соблюдения некоторых правил контроля доступа для пакетов, пересылаемых с сайта B в нашу сеть WireGuard, мы могли бы вместо этого построить отдельную цепочку только для него, переходя от цепочки forward к ней для дополнительной фильтрации. В этом случае вместо forward этого добавьте в цепочку следующие два правила:
ct state established,related accept
iif $pub_iface oifname $wg_iface goto site-b-forward
Затем добавьте в таблицу filter следующую цепочку site-b-forward:
chain site-b-forward {
# пересылать HTTP-пакеты из конечной точки B в конечную точку A
ip saddr 192.168.200.22 ip daddr 10.0.0.1 tcp dport http accept
# отклонить с вежливым "административно запрещено" ответом icmp
reject with icmpx type admin-prohibited
}
Последнее правило в цепочке отклоняет весь явно не принятый трафик (т.е. большинство типов новых подключений), отбрасывая его и отвечая пакетом ICMP или ICMPv6 «Пункт назначения недоступен (обмен данными административно запрещен)» . До этого у нас есть правила доступа WireGuard VPN. В приведенной выше версии мы разрешаем подключения к HTTP-серверу конечной точки A (10.0.0.1 TCP-порт 80) только с конечной точки B (192.168.200.22).
Поскольку правило DNAT из цепочки prerouting (с привязкой prerouting к типу nat) выполняется до этого правила управления доступом в цепочке forward (с привязкой forward к типу filter), к этому моменту пакеты, первоначально отправленные с конечной точки B на TCP-порт 80 хоста β, уже будут транслированы в точку A с IP-адресом 10.0.0.1. Таким образом, это правило управления доступом позволит пересылать эти пакеты (при блокировании любых подобных пакетов, отправленных с других хостов на сайте B). См. документацию Netfilter Hooks для получения дополнительных сведений о потоках пакетов и порядке обработки.
Если бы на конечной точке A (и других конечных точках, которые мы могли бы добавить в сеть WireGuard, например, 10.0.0.4и 10.0.0.5) было несколько сервисов, к которым мы хотели бы разрешить доступ конечной точке B и нескольким другим хостам на сайте B, мы могли бы добавить дополнительные правила, чтобы разрешить доступ к этим дополнительным услугам, например следующим образом:
ip saddr 192.168.200.22 ip daddr 10.0.0.1 tcp dport 80 accept
ip saddr 192.168.200.123 ip daddr 10.0.0.1 tcp dport 80 accept
ip saddr 192.168.200.22 ip daddr 10.0.0.1 tcp dport 443 accept
ip saddr 192.168.200.22 ip daddr 10.0.0.1 tc4 dport 993 accept
ip saddr 192.168.200.22 ip daddr 10.0.0.4 tcp dport 80 accept
ip saddr 192.168.200.123 ip daddr 10.0.0.5 tcp dport 80 accept
Мы могли бы объединить их все в одном правиле, как это (где «.» является оператором конкатенация nftables):
ip saddr . ip daddr . tcp dport {
192.168.200.22 . 10.0.0.1 . 80,
192.168.200.123 . 10.0.0.1 . 80,
192.168.200.22 . 10.0.0.1 . 443,
192.168.200.22 . 10.0.0.1 . 993,
192.168.200.22 . 10.0.0.4 . 80,
192.168.200.123 . 10.0.0.5 . 80
} accept
Полный файл /etc/conf.d/nftables для хоста β с оригинальной версией цепочки site-b-forward (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51822
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# accept all loopback packets
# принять все петлевые пакеты
iif "lo" accept
# accept all icmp/icmpv6 packets
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# accept all packets that are part of an already-established connection
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain site-b-forward {
# пересылать HTTP-пакеты из конечной точки B в конечную точку A
ip saddr 192.168.200.22 ip daddr 10.0.0.1 tcp dport http accept
# отклонить с вежливым "административно запрещенным" ответом icmp
reject with icmpx type admin-prohibited
}
chain forward {
type filter hook forward priority 0; policy drop;
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# фильтровать все пакеты с сайта B в WireGuard VPN через цепочку site-b-forward
iif $pub_iface oifname $wg_iface goto site-b-forward
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
}
table inet nat {
chain prerouting {
type nat hook prerouting priority -100; policy accept;
# перезаписываем адрес назначения всех пакетов TCP-порта 80 на 10.0.0.1
tcp dport http dnat ip to 10.0.0.1
}
}
Проверка
Проверьте это, попытавшись получить доступ к HTTP-серверу точки А из точки В через перенаправленный TCP-порт 80 на хосте β ( 192.168.200.2):
$ curl 192.168.200.2
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
...
Вы должны увидеть напечатанный HTML-код домашней страницы точки B. Если вы запустите другой веб-сервер, работающий на точке B, на каком-либо другом порту, например, TCP-порт 8080 (запускается python3 -m http.server 8080 для временного сервера, обслуживающего содержимое текущего каталога), вы не сможете получить к нему доступ из точки A (или где-либо еще):
$ curl 192.168.200.2 :8080
curl: (7) Failed to connect to 192.168.200.2 port 8080: Connection refused
С сайта на сайт
С топологией «сайт-сайт» брандмауэр nftables для каждого из сайтов будет очень похож на брандмауэр для сайта в топологии «точка-сайт», но проще, поскольку NAT не требуется.
В качестве примера мы будем использовать межсайтовый WireGuard VPN, описанный в руководстве WireGuard Site to Site Configuration . Вот сетевая диаграмма сценария:
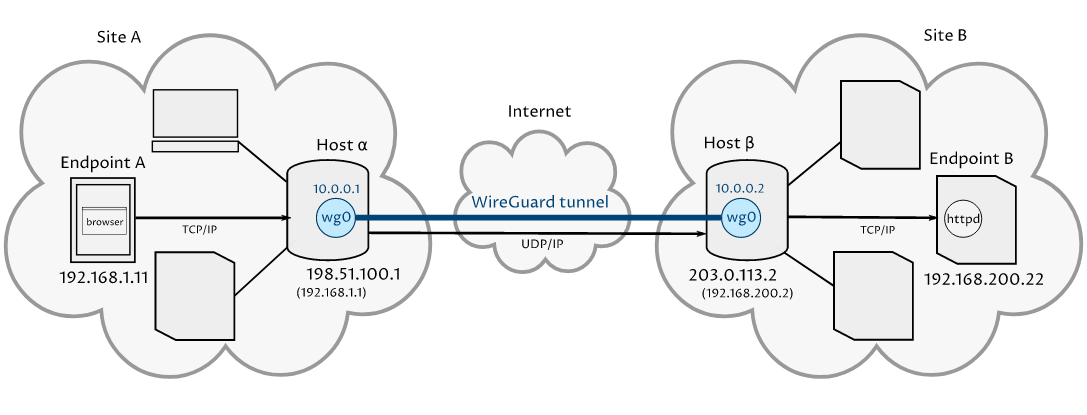
Рисунок 5. Сценарий от сайта к сайту
В этом сценарии конечная точка A на сайте A отправляет HTTP- запросы к конечной точке B на сайте B. Эти запросы маршрутизируются через WireGuard VPN между хостом α на сайте A и хостом β на сайте B. Ни конечная точка A, ни конечная точка B не являются частью WireGuard VPN.
Оконечная точка А
Брандмауэр nftables для конечной точки A может просто использовать базовую конфигурацию ; и поскольку конечная точка A не имеет ничего общего с WireGuard, вы можете исключить строку iif $pub_iface udp dport $wg_port accept из нее.
Конечная точка B
Брандмауэр nftables для конечной точки B также может использовать базовую конфигурацию с исключённой строкой iif $pub_iface udp dport $wg_port accept. Однако он должен принимать HTTP- соединения, поэтому добавьте правило, подобное следующему, в конец цепочки input таблицы filter (прямо над правилом reject):
tcp dport http accept
Это позволит любому хосту, который может подключиться к конечной точке B, получить доступ к своему HTTP- серверу. Чтобы ограничить доступ, чтобы только конечная точка A ( 192.168.1.11) могла получить доступ к своему HTTP- серверу, используйте вместо этого это правило:
ip saddr 192.168.1.11 tcp dport http accept
Хост α
На хосте α мы снова можем использовать нашу базовую конфигурацию nftables с некоторыми дополнениями. Нам нужно изменить его определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на хосте α:
define wg_port = 51821
Также в верхней части конфигурации добавим определение для нашего имени интерфейса WireGuard:
define wg_iface = "wg0"
Затем в цепочке forward его таблицы filter, если мы хотим разрешить неограниченный доступ с любого хоста на сайте B к любому хосту на сайте A, мы могли бы добавить следующие два правила (прямо перед правилом reject with icmpx type host-unreachable):
iifname $ wg_iface accept
oifname $ wg_iface accept
==Предупреждение==
Для правил nftables, ссылающихся на физические интерфейсы, которые не открываются или не отключаются, используйтеiif(входной интерфейс по индексу) илиoif(выходной интерфейс по индексу).
Для виртуальных интерфейсов, которые могут быть активированы или отключены, например интерфейсов WireGuard, используйтеiifname(входной интерфейс по имени) иoifname(выходной интерфейс по имени).
Правила, построенные сiifиoifвыражением хранят ссылки на индекс интерфейса в то время правило было загружено . Это позволяет немного ускорить выполнение правила, но если интерфейс будет отключен, а затем снова восстановлен, индекс изменится, и правило перестанет работать.
Однако, если мы хотим ограничить доступ с сайта B таким образом, чтобы хосты в сайте B могли отвечать только на соединения, инициированные в сайте A (например, отвечать на HTTP-запросы, сделанные хостами в сайте A), а не инициировать какие-либо подключения к сайту A сами, мы могли бы вместо этого построить небольшую цепочку, прыгая на нее с цепочки forward. В этом случае добавьте взамен в цепочку forwardследующие два правила:
iifname $ wg_iface goto wg-forward oifname $ wg_iface accept
Затем добавьте в таблицу filter следующую цепочку wg-forward:
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# отклонить с вежливым "административно запрещено" ответом icmp
reject with icmpx type admin-prohibited
}
Первые правила в этой цепочке перенаправляют весь трафик ICMP и ICMPv6 с любого хоста на сайте B на любой хост на сайте A, а также трафик для любых уже установленных соединений. Последнее правило в цепочке отклоняет весь явно не принятый трафик (т.е. любые новые соединения), отбрасывая его и отвечая пакетом ICMP или ICMPv6 «Пункт назначения недоступен (обмен данными административно запрещен)» .
Если бы мы хотели разрешить доступ к нескольким конкретным службам на сайте A с сайта B, мы бы добавили дополнительные правила доступа в середину этой цепочки (как мы это сделаем для хоста β ниже). Но так как мы не должны предоставлять какой либо другой доступ к этому сценарию, полный файл /etc/conf.d/nftables хоста α (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51822
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# отклонить с вежливым "административно запрещенным" ответом icmp
reject with icmpx type admin-prohibited
}
chain forward {
type filter hook forward priority 0; policy drop;
# фильтровать все пакеты, входящие с сайта B на сайт A через цепочку wg-forward
iifname $wg_iface goto wg-forward
# разрешить всем исходящим пакетам с сайта A на сайт B
oifname $wg_iface accept
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
}
Хост β
Конфигурация nftables для хоста β будет почти такой же, как и для хоста α (за исключением того, что он также предоставит доступ конечной точке A для инициирования подключений к конечной точке B).
Мы начнем с нашей базовой конфигурации nftables и изменим ее определение wg_port, чтобы оно соответствовало порту, используемому для настройки WireGuard на хосте β :
define wg_port = 51822
Также в верхней части конфигурации добавьте определение для нашего имени интерфейса WireGuard:
define wg_iface = "wg0"
Поскольку мы хотим использовать Хост β для обеспечения соблюдения некоторых правил управления доступом для сайта B, — создадим отдельную цепочку фильтров для доступа через его соединение WireGuard с сайтом A. Добавьте следующие два правила в цепочку forward таблицы filter:
iifname $ wg_iface goto wg-forward
oifname $ wg_iface accept
Затем добавьте в таблицу filter следующую цепочку wg-forward:
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 192.168.200.22 tcp dport http accept
# отклонить с вежливым "административно запрещено" ответом icmp
reject with icmpx type admin-prohibited
}
Первые правила в этой цепочке перенаправляют весь трафик ICMP и ICMPv6 с любого хоста на сайте B на любой хост на сайте A, а также трафик для любых уже установленных соединений. Последнее правило в цепочке отклоняет весь явно не принятый трафик (т.е. большинство типов новых подключений), отбрасывая его и отвечая пакетом ICMP или ICMPv6 «Пункт назначения недоступен (обмен данными административно запрещен)» .
Посередине у нас есть правила доступа WireGuard VPN. В приведенной выше минимальной версии мы разрешаем все подключения к HTTP-серверу конечной точки B (192.168.200.22 TCP-порт 80) с любого узла сайта A.
Более строгая версия этого правила может разрешить только конечной точке A (192.168.1.11) доступ к HTTP-серверу конечной точки B :
ip saddr 192.168.1.11 ip daddr 192.168.200.22 tcp dport http accept
Если есть различные сервисы на оконечной точке В, которым мы желаем разрешить доступ к точке А, — мы можем изменить это правило, чтобы разрешить эти дополнительные сервисы, подобно следующим (разрешают доступ к TCP портам 22, 80, 8080 и 8081):
ip saddr 192.168.1.11 ip daddr 192.168.200.22 tcp dport { ssh, http, 8080, 8081 } accept
Если бы на сайте A есть несколько других хостов, которым мы хотели бы разрешить доступ к оконечной точке B, — мы можем настроить правило, разрешающее этим хостам доступ к HTTP-серверу на оконечной точке B:
ip saddr { 192.168.1.11, 192.168.1.14, 192.168.1.15 } ip daddr 192.168.200.22 tcp dport http accept
В вышеупомянутых случаях мы можем в качестве альтернативы добавить несколько отдельных правил для каждого отдельного хоста или службы; но с nftables немного эффективнее использовать наборы IP-адресов или портов в рамках одного правила (хотя вы заметите разницу только случае, если у вас много трафика или много правил).
В случаях, когда у нас есть несколько похожих правил, но с разными комбинациями исходного IP-адреса и целевого IP-адреса или порта, мы также можем использовать набор nftables с конкатенацией, чтобы объединить их все в одно правило. Например, если бы у нас была группа похожих правил, таких как следующие:
ip saddr 192.168.1.11 ip daddr 192.168.200.22 tcp dport http accept
ip saddr 192.168.1.14 ip daddr 192.168.200.22 tcp dport http accept
ip saddr 192.168.1.15 ip daddr 192.168.200.123 tcp dport http accept
ip saddr 192.168.1.11 ip daddr 192.168.200.123 tcp dport smtp accept
ip saddr 192.168.1.15 ip daddr 192.168.200.123 tcp dport smtp accept
Мы могли бы объединить их все в одном правиле , как это (где .является конкатенация оператор nftables):
ip saddr . ip daddr . tcp dport {
192.168.1.11 . 192.168.200.22 . http,
192.168.1.14 . 192.168.200.22 . http,
192.168.1.15 . 192.168.200.123 . http,
192.168.1.11 . 192.168.200.123 . smtp,
192.168.1.15 . 192.168.200.123 . smtp
} accept
==Примечание==
При использовании обоих IPv4 и IPv6-адреса, вам нужно отдельноеip6-правило (с одинаковым аргументамиsaddrиdaddr) для адресов IPv6 - вы не можете смешивать адреса IPv4 и IPv6 в одном выражении.
Полный файл /etc/conf.d/nftables для хоста β с минимальной цепочкой wg-forward (за вычетом таблиц drop-bad-packets и drop-bad-ct-states) будет выглядеть следующим образом:
#!/usr/sbin/nft -f
flush ruleset
define pub_iface = "eth0"
define wg_iface = "wg0"
define wg_port = 51822
table inet filter {
chain input {
type filter hook input priority 0; policy drop;
# принять все петлевые пакеты
iif "lo" accept
# принять все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# принять все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# принять все SSH-пакеты, полученные через публичный интерфейс
iif $pub_iface tcp dport ssh accept
# принять все пакеты WireGuard, полученные на общедоступном интерфейсе
iif $pub_iface udp dport $wg_port accept
# отклонить с вежливым ответом icmp "порт недоступен"
reject
}
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# пересылать все HTTP-пакеты для конечной точки B
# forward all HTTP packets for Endpoint B
# отклонить с вежливым "административно запрещенным" ответом icmp
# reject with polite "administratively prohibited" icmp response
}
chain forward {
type filter hook forward priority 0; policy drop;
# фильтровать все пакеты, входящие с сайта A на сайт B через цепочку wg-forward
iifname $wg_iface goto wg-forward
# разрешить всем исходящим пакетам с сайта B на сайт A
oifname $wg_iface accept
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
}
Проверьте это, попытавшись получить доступ к HTTP-серверу точки А из точки В через перенаправленный TCP-порт 80 на хосте β ( 192.168.200.2 2):
$ curl 192.168.200.22
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
...
Вы должны увидеть напечатанный HTML-код домашней страницы точки B. Если вы запустите другой веб-сервер, работающий на точке B, на каком-либо другом порту, например, TCP-порт 8080 (запускается python3 -m http.server 8080 для временного сервера, обслуживающего содержимое текущего каталога), вы не сможете получить к нему доступ из точки A (или где-либо еще):
$ curl 192.168.200.22:8080
curl: (7) Failed to connect to 192.168.200.22 port 8080: Connection refused
Исправление проблем
Ping
Используйте инструменты ICMP , такие как ping, для проверки маршрутизации, а не контроля доступа . Например, наш сценарий брандмауэра «сайт-сайт» выше позволяет любому хосту на сайте A пинговать любой хост на сайте B, и наоборот. Это позволяет вам убедиться, что маршрутизация между сайтом A и сайтом B работает.
Чтобы проверить, что ваш брандмауэр работает, попробуйте подключиться к определенным службам, которые ваш брандмауэр должен разрешать или запрещать. Например, наш наш сценарий брандмауэра «сайт-сайт» выше только позволяет HTTP соединения от точки A до конечной точки B. Вы можете проверить это с помощью HTTP-инструмента , как curl (или веб-браузера).
Tcpdump
Tcpdump — отличный универсальный инструмент для устранения сетевых проблем. В частности, для проблем с брандмауэром вы можете использовать его, чтобы определить, проходят ли пакеты, как ожидается, от данного хоста. Например, в сценарии «сайт-сайт» , если вы не видите выходных данных при попытке подключиться от точки A к конечной точке B (т.е. во время работы curl 192.168.200.22), попробуйте выполнить следующую команду на каждом хосте на пути между точкой A и конечной точкой B (точка A, Хост α, Хост β и Конечная точка B):
$ sudo tcpdump -ni any 'tcp port 80 and host 192.168.200.22'
Пока эти команды tcpdump выполняются, попробуйте снова подключиться от конечной точки A к конечной точке B. Вы должны увидеть, как каждый терминал, на котором запущен tcpdump, напечатает серию строк, которые выглядят следующим образом:
22:12:16.156120 IP 192.168.1.11.36112 > 192.168.200.22.80: Flags [S], seq 767605079, win 62167, options [mss 8881,sackOK,TS val 1689421470 ecr 0,nop,wscale 6], length 0
22:12:16.157801 IP 192.168.200.22.80 > 192.168.1.11.36112: Flags [S.], seq 3979107600, ack 767605080, win 62083, options [mss 8881,sackOK,TS val 3921390190 ecr 1689421470,nop,wscale 6], length 0
22:12:16.158587 IP 192.168.1.11.36112 > 192.168.200.22.80: Flags [.], ack 1, win 972, options [nop,nop,TS val 1689421475 ecr 3921390190], length 0
22:12:16.158637 IP 192.168.1.11.36112 > 192.168.200.22.80: Flags [P.], seq 1:78, ack 1, win 972, options [nop,nop,TS val 1689421475 ecr 3921390190], length 77: HTTP: GET / HTTP/1.1
22:12:16.158755 IP 192.168.200.22.80 > 192.168.1.11.36112: Flags [.], ack 78, win 969, options [nop,nop,TS val 3921390191 ecr 1689421475], length 0
Строки с 192.168.1.11.36112 > 192.168.200.22.80 представляют пакеты, отправляемые на TCP-порт конечной точки B 80, а строки с 192.168.200.22.80 > 192.168.1.11.36112 представляют пакеты, отправляемые обратно из конечной точки B в ответ. Если команда tcpdump на хосте выводит только строки с первым и ни одного с последним, это означает, что только пакеты, отправленные в конечную точку B, достигают хоста — никакие пакеты на обратном пути из конечной точки B не поступают. Если команда tcpdump на хосте ничего не выводит, это означает, что никакие пакеты не достигают хоста, даже те, которые находятся на первом этапе пути к конечной точке B.
Логирование
Вы можете использовать операторы log nftables для регистрации пакетов, которые попадают в различные точки ваших цепочек. Например, вы можете добавить простой оператор log в цепочку wg-forward хоста β в примере сценария «сайт-сайт», чтобы регистрировать все пакеты, которые собираются отклонить:
chain wg-forward {
# пересылать все пакеты icmp / icmpv6
ip protocol icmp accept
ip6 nexthdr ipv6-icmp accept
# пересылать все пакеты, которые являются частью уже установленного соединения
ct state established,related accept
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 192.168.200.22 tcp dport http accept
log
# отклонить с вежливым "административно запрещено" ответом icmp
reject with icmpx type admin-prohibited
}
Любой пакет, попавший в этот оператор журнала, будет записан в средство сообщений ядра. Вы можете просмотреть эти сообщения с помощью команды dmesg; или, если ваша система настроена с помощью journald, с помощью journalctl -k ``команды; или если ваша система использует rsyslogd, эти сообщения часто будут записываться в файлы с именами /var/log/kern.log или /var/log/messages.
Например, если вы попытаетесь запустить curl 192.168.200.22:8080 из конечной точки A в примере с «сайт-сайт», вы увидите такое сообщение:
Nov 17 19:21:56 host-beta kernel: IN=wg0 OUT=ens5 MAC= SRC=192.168.1.11 DST=192.168.200.22 LEN=60 TOS=0x00 PREC=0x00 TTL=63 ID=58474 DF PROTO=TCP SPT=43678 DPT=8080 WINDOW=62167 RES=0x00 SYN URGP=0
Вы можете ограничить количество регистрируемых пакетов, добавив выражение перед оператором log; например, чтобы регистрировать только пакеты, полученные от оконечной точки A (192.168.1.11 в примере «сайт-сайт»), используйте следующий оператор:
ip saddr 192.168.1.11 log
И вы можете указать уровень журнала для сообщений (по умолчанию warn), а также добавить к ним собственный префикс:
log level info prefix "wg-filter reject: "
Вы можете также регистрировать пакеты , которые соответствуют конкретному правилу — просто вставить в заявлении log в конце правила (но до любого заявления завершающего как accept, drop, jump и т.д.):
# пересылать все HTTP-пакеты для конечной точки B
ip daddr 192.168.200.22 tcp dport http log level debug prefix "new conn to endpoint b: " accept
Трассировка
Трассировка с помощью nftables также может быть полезна при попытке устранить проблему. Он покажет вам, какие именно пакеты рассматриваются и какие правила из какой цепочки применяются к пакету.
Например, вы можете включить трассировку, добавив оператор meta nftrace set 1 в цепочку forward хоста β в примере от «сайт-сайт». Это будет отслеживать пакеты по мере их движения по цепочке forward (а также любой другой цепочке, в которую они переходят после нее):
chain forward {
type filter hook forward priority 0; policy drop;
meta nftrace set 1
# фильтровать все пакеты, входящие с сайта A на сайт B через цепочку wg-forward
iifname $wg_iface goto wg-forward
# разрешить всем исходящим пакетам с сайта B на сайт A
oifname $wg_iface accept
# отклонить с вежливым ответом icmp "хост недоступен"
reject with icmpx type host-unreachable
}
Используйте следующую команду, чтобы наблюдать за этими следами по мере их появления:
$ sudo nft monitor trace
Если вы попытаетесь запустить curl 192.168.200.22:8080 из конечной точки A в примере от «сайт-сайт» , вы увидите следующий результат:
trace id 053f9724 inet filter forward packet: iif "wg0" oif "eth0" ip saddr 192.168.1.11 ip daddr 192.168.200.22 ip dscp cs0 ip ecn not-ect ip ttl 63 ip id 48759 ip protocol tcp ip length 60 tcp sport 43682 tcp dport 8080 tcp flags == syn tcp window 62167
trace id 053f9724 inet filter forward rule iifname "wg0" oif "ens5" goto wg-forward (verdict goto wg-forward)
trace id 053f9724 inet filter wg-forward rule ct state established,related accept (verdict continue)
trace id 053f9724 inet filter wg-forward rule reject with icmpx type admin-prohibited (verdict drop)
1В оригинальной статье — «Hub and Spoke»