Пересборку мира лучше делать, например в tty2 (из иксов переход по Ctrl+Alt+F2, обратно Ctrl+Alt+F7) с выводом информации в файл командой emerge -e --keep-going system world > /home/my-emerge.log > /dev/tty2
В случае сбоя иксов - пересборка не прервется, а посмотреть пропущенный пакет всегда можно будет в файле /home/my-emerge.log
Спасибо за обстоятельный совет. Сейчас аккуратно допишу в /etc/make.conf и /usr/src/linux/Makefile, наконец вычищу конфигурацию ядра от неиспользуемых драйверов и пересоберу еще разок. А вот world уже дома буду - с постоянным коннектом и питанием на ближайшие двое суток.
Но сначала - gcc
А вот с gcc вновь незадача -
*warning: gcc/cc1-checksum.o differs
warning: gcc/cc1plus-checksum.o differs
Bootstrap comparison failure!
gcc/builtins.o differs
make[2]: ***** [compare] Ошибка 1
make[2]: Выход из каталога `/var/calculate/tmp/portage/sys-devel/gcc-4.5.3-r1/work/build’
make[1]: ***** [stage3-bubble] Ошибка 2
make[1]: Выход из каталога `/var/calculate/tmp/portage/sys-devel/gcc-4.5.3-r1/work/build’
make: ***** [bootstrap-lean] Ошибка 2
emake failed*
В общем - не собрался gcc…
Я посмотрел логи, складывается впечатление, что строка ключей тупо добавляется к строке вида
"-O2 -g0 -Wno-all -pipe"
(условно, просто как пример) и, вполне возможно, что в этих двух строках взаимоисключающие аргументы (на что, возможно, я и напоролся). Я закомментировал для проверки догадки в make.conf строки:
#BOOT_CFLAGS="${CFLAGS}"
#T_CFLAGS="${CFLAGS}"
и компилятор, естественно, собрался.
чтобы не разбираться, что где мешает, выкинул большую часть из CFLAGS, т.к. полагаю, что в “строкодробилке” часть, которая отвечает за циклы не особо и критична - все равно все замедляется работой с файловой системой.
Странно. На Atom N270 тоже 3,5 суток… с этими параметрами. На Atom N570 не больше 2 суток должно занимать. Единственно что могу сказать эти параметры примерно в 2 раза увеличивают время компиляции пакетов, но, на мой взгляд, оно того стоит.
Во-первых, может быть скорость сборки в большей степени определяется уже скоростью работы с дисковой подсистемой? И сам компилятор (в смысле работы) уже не особо критичен?
А во-вторых еще появился вопрос. Судя по описанию комилятора, существует возможность задать опцию -mtune=atom, которая, если верить описанию, определяет следующую поддержку: Intel Atom CPU with 64-bit extensions, MMX, SSE,SSE2, SSE3 ans SSSE3 instruction set support Может быть воткнуть этот ключ и заодно избавиться от ключей -mmmx -msse -msse2 -msse3 -mssse3 точно, а также, возможно, и от ключей *-msahf mcx16* ? При указании семейства, полагаю, компилятор автоматом должен включить эти ключи. Кроме того, возможе ли вариант, что указание ключа позволит как минимум избежать прямого указания кэша первого уровня? А второй указать явно - 256К.
Самое странное, что замена native на atom давала негативный результат. Хотя это более чем странно. Но попробовать стоит и замерить результаты, так как данная замена позволяет использовать распределенную компиляцию на группе компьютеров с использованием distcc и, возможно, ситуация изменилась уже в лучшую сторону. Другие предположения также нуждаются в проверке. В некоторых случаях gcc не включает опции, которые по идее должны быть включены. Именно по этому делал акцент на параметры, от которых зависит ощутимый вклад в увеличение производительности.
несмотря на то, что четко прописанные ключи гарантируют заведомо лучший результат, использование в ключах компиляции семейства процессоров взамен детального уточнения видов инструкций позволяет получить результат, не намного хуже результата, получающегося при использовании предельно детализированной строки ключей компилятора.
Цитата “Вывод, на мой взгляд, следующий: несмотря на то, что четко прописанные ключи гарантируют заведомо лучший результат, использование в ключах компиляции семейства процессоров взамен детального уточнения видов инструкций позволяет получить результат, не намного хуже результата, получающегося при использовании предельно детализированной строки ключей компилятора.”
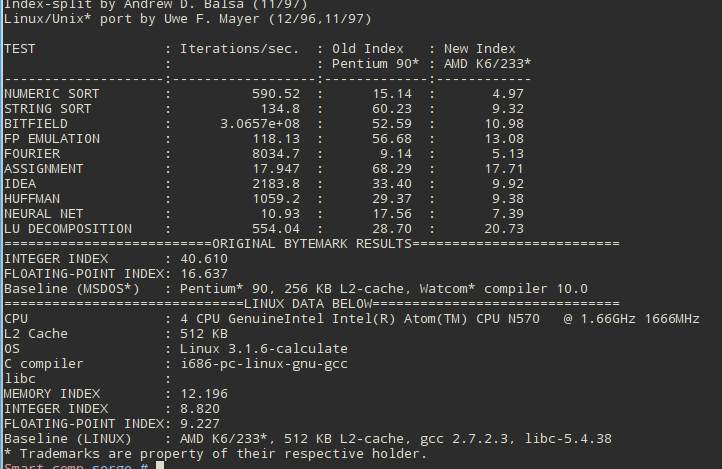
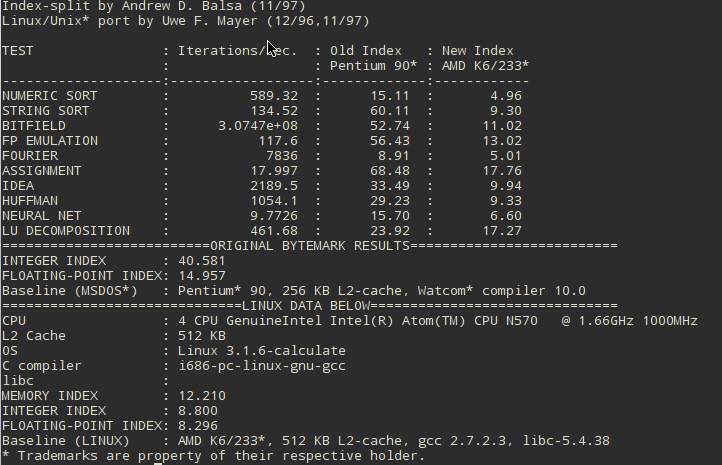
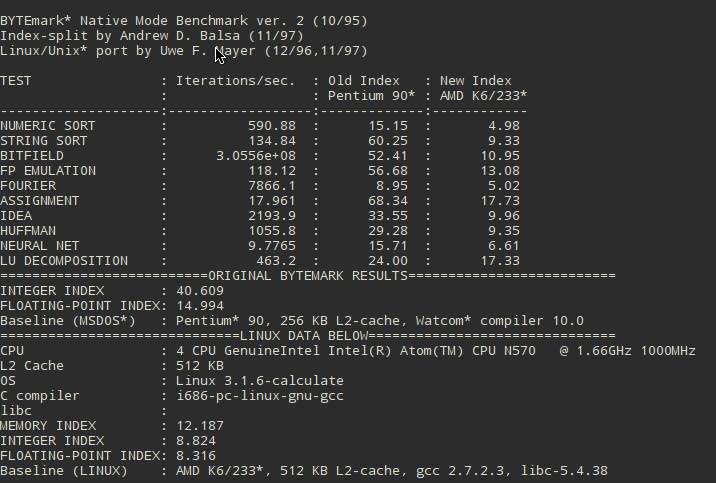
В общей оценке производительности системы потеря 5-10% не сильно заметна. Но… в некоторых задачах будет приличное проседание. В тесте NEURAL NET разрыв в 1 балл это значительный провал в производительности. В тесте LU DECOMPOSITION разрыв в 100 баллов это почти на 17% больше затраченного времени на некоторых задачах.
P.S.
За тесты спасибо. Жаль, что до сих пор не выправили параметры для процессора atom в компиляторе gcc 4.5.3. В версиях 4.6+ все обстоит еще хуже - наблюдается регресс.
P.P.S.
Почему то не работает форматирование текста в сообщениях.
Во-первых, может быть скорость сборки в большей степени определяется уже скоростью работы с дисковой подсистемой? И сам компилятор (в смысле работы) уже не особо критичен?
Только если мало оперативной памяти.
А так вполне логично. Всякие “кЕши” спасают только на забегах с короткой дистанцией или при “круговых” бегах вокруг “стадиона”, когда основная масса критичного кода всегда в кеш памяти. В остальных случаях потеря производительности ошеломляет. Представьте бегуна на старте с хорошими кроссовками для бега, когда после старта секунд через 10 покрытие с хорошим сцеплением вдруг переходит в ледовое…